

Semantičko pretraživanje u BHS: Pustolovina u distilaciji znanja
Implementacija efikasne semantičke pretrage u sistem za upravljanje radnim procesima, posebno za jezike sa ograničenim prethodno obučenim modelima, predstavlja intrigantan zadatak. Krenuli smo na ovaj put sa bosansko-hrvatsko-srpskim jezikom (BHS), suočeni sa ograničenim resursima i nedostatkom gotovih rješenja. Naš odgovor je bio pronađen u fleksibilnoj metodi pod nazivom distilacija znanja. Ovaj članak istražuje naše iskustvo i inovativnu implementaciju ove metode.
Prelazak na semantičku pretragu
Tradicionalne metode pretrage, ograničene svojim pristupom zasnovanim na ključnim riječima, često se bore da uhvate suštinu i kontekst korisničkih upita. Nuansirane, svjesne konteksta sposobnosti semantičke pretrage, koje su sposobne pružiti precizne i relevantne rezultate, učinile su je jasnim izborom za naš sistem upravljanja radnim procesima.
Razumijevanje distilacije znanja
U osnovi, distilacija znanja se odnosi na prenošenje saznanja sa "učiteljskog" modela na "učenik" model. "Učitelj" je veliki model, obučen na obimnim skupovima podataka poput engleskog MS MARCO-a. "Učenik" je manji, efikasniji model. Cilj je zadržati detaljno razumijevanje učiteljskog modela, istovremeno čineći učenički model okretan i efikasan.
Evo kako to funkcioniše: Učiteljski model generiše ugrađivanje za englesku rečenicu, koja je cilj. Učenički model generiše ugrađivanje za prevedenu rečenicu na BHS. Cilj je da izlaz učeničkog modela bude što sličniji cilju učiteljskog modela. To se postiže smanjenjem funkcije gubitka između ta dva ugrađivanja, postepenim prilagođavanjem parametara učeničkog modela.
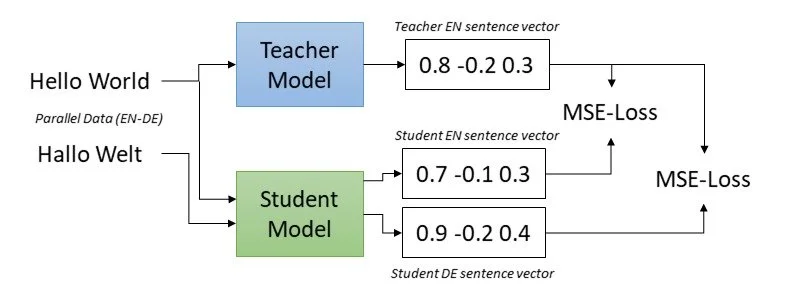
Iskorištavanje distilacije znanja za efikasne rezultate sa kontekstom
Izbor distilacije znanja
Stvaranje jezičkog modela za BHS moglo bi biti mukotrpan zadatak, s obzirom na potrebu za značajnim računarskim resursima i specijalizovanim skupovima podataka za obuku. S obzirom na složenosti obuke velikog jezičkog modela (VJM) i nedostatak grafičkih procesora (GPU), distilacija znanja se pokazala pragmatičnijim pristupom.
S obzirom na dostupnost dobro obučenih engleskih modela, uspjeli smo iskoristiti uvide tih modela da bismo obučili BHS model. Ovaj pristup nam je pomogao ne samo da uhvatimo nijansirani kontekst BHS jezika, već nam je omogućio i fino podešavanje našeg modela za jedinstvene karakteristike upotrebe BHS jezika. Dodatna prednost bila je poboljšana efikasnost bez kompromisa u performansama, ključni zahtjev za skaliranje našeg sistema.
Rezultati i budući koraci
Primjena distilacije znanja pomogla nam je da integrišemo efikasnu lokalnu semantičku pretragu u naš sistem upravljanja radnim procesima. Potencijal ovakvog alata je ogroman, posebno kada se kombinuje sa modelima za sažimanje. To otvara mogućnosti poput pružanja sažetog pregleda najboljih rezultata pretrage ili olakšavanja "razgovorne" interakcije sa podacima koji se čuvaju u našem sistemu, OWIS.
Iako je naše trenutno rješenje pokazalo obećavajuće rezultate, vidimo put ka daljnjem usavršavanju. Sada se okrećemo učenju jačanja na osnovu povratnih informacija korisnika (RLHF), gdje planiramo fino podešavanje našeg BHS modela na osnovu povratnih informacija korisnika, usklađujući ga što više sa sadržajem koji se čuva u OWIS-u.
Naše putovanje u lokalizaciji semantičke pretrage pomoću distilacije znanja pokazalo je kako se tehnički izazovi mogu prevazići inovativnim rješenjima. Uspjeli smo stvoriti BHS model koji pruža precizne rezultate svjestan konteksta, efikasno koristeći uvide prethodno postojećih engleskih modela. Dok nastavljamo da usavršavamo svoj pristup i istražujemo uzbudljive integracije, budućnost se čini ispunjenom mogućnostima za još efikasnije i interaktivnije angažovanje sa podacima. Ostanite u toku za više informacija o našem ongoing inovativnom putovanju.