

Pioneering Semantic Search in BHS: An Adventure in Knowledge Distillation
Implementing an efficient semantic search feature in a workflow management system, particularly for languages with limited pre-trained models, is an intriguing task. We embarked on this journey with the Bosnian, Croatian, Serbian language (BHS), faced with limited resources and an absence of ready-made solutions. Our answer was found in a versatile method called Knowledge Distillation. This article explores our journey and the innovative implementation of this method.
Shifting to Semantic Search
Traditional search methods, limited by their keyword-oriented approaches, often struggle to capture the essence and context of user queries. The nuanced, context-aware capabilities of semantic search, capable of delivering precise and relevant results, made it a clear choice for our workflow management system.
Deciphering Knowledge Distillation
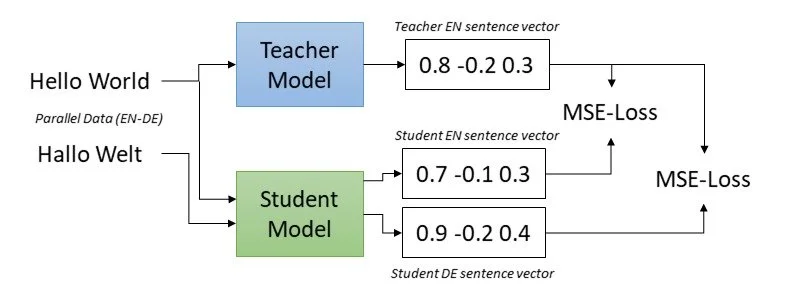
At its core, Knowledge Distillation is about transferring insights from a 'teacher' model to a 'student' model. The 'teacher' is a large model, trained on extensive datasets like the English MS MARCO. The 'student' is a smaller, efficient model. The objective is to retain the detailed understanding of the teacher model while making the student model nimble and efficient.
Here's how it works: The teacher model generates an embedding for an English sentence, which is the target. The student model generates the embedding for the translated sentence in BHS. The goal is to make the student model's output closely resemble the teacher model's target. This is achieved by reducing the loss function between the two embeddings, progressively adjusting the student model's parameters.
Unleashing Semantic Search for BHS: Harnessing Knowledge Distillation for Efficient and Context-Aware Results
The Choice of Knowledge Distillation
Creating a language model for BHS could have been a laborious task, given the need for significant computational resources and specialized training data. Considering the complexities of training a large language model (LLM) and the scarcity of GPUs, we found Knowledge Distillation to be a more pragmatic approach.
With the availability of well-performing English models, we were able to utilize the insights of these models to train a BHS student model. This approach not only helped in capturing the nuanced context of BHS but also enabled us to fine-tune our model for the unique characteristics of BHS language usage. The added bonus was an improved efficiency without compromising the performance, a key requirement for scaling our system.
Results and Future Steps
The application of Knowledge Distillation helped us integrate an efficient, local language semantic search into our workflow management system. The potential of such a tool is vast, especially when coupled with summarization models. It opens up possibilities like providing a summarized overview of the top search results or facilitating a more 'conversational' interaction with the data stored in our system, OWIS.
While our current solution has shown promising results, we see a path to further refinement. We are now looking towards Reinforcement Learning from Human Feedback (RLHF), where we plan to fine-tune our BHS model based on user feedback, aligning it more closely with the content stored in OWIS.
Conclusion
Our journey in localizing semantic search with Knowledge Distillation has shown how technical challenges can be met with innovative solutions. We have managed to create a BHS model that offers precise, contextually aware results by effectively utilizing the insights of pre-existing English models. As we continue refining our approach and explore exciting integrations, the future seems filled with possibilities for even more efficient and interactive data engagement. Stay tuned for more updates on our ongoing innovation journey.